Sono anni che parlo dei prodotti BlackMagic Design, e ho dedicato tanti articoli alla Pocket 4k, una innovativa camera che registra in prores, Braw, e ha cambiato il modo di lavorare di tante persone.
Oggi 19 dicembre 2024 Blackmagic Design fa il regalo di Natale a tutti i videomaker, abbassa definitivamente il prezzo della camera a meno di 1000$ !!!
per chi non fosse convinto, qui trovate il mio articolo :
In passato con precendenti articoli dedicati ai codec dei sistemi operativi, ho parlato di conoscenze di base con Zuppa 1, di come non serva installare codec esterni per montare in Zuppa 2, ho parlato dei Digital Intermediate in Flussi Digitali, e di codec Audio in Ac3 siamo a piedi, oggi siamo qui a chiarire un fatto che recentemente ha creato un certo numero di rumors, di chiacchiere da bar inutili, e soprattutto preoccupazioni ingiustificate, ovvero l’annuncio di Apple che dai sistemi operativi dopo Mojave, 10.14, non saranno più supportati i codec Cineform, DnxHr, e altri considerati obsoleti.
Facciamo un paio di semplici domande: oggi sono supportati? NO!!!
come si può leggere sui formati supportati da FinalCutProX sulla pagina di Apple.
Ma ovviamente saranno supportati dal sistema operativo? NO!!!
Nè Apple Osx, nè Windows da Xp all’ultimo Win10 supportano tali codec.
Quindi ci sono pagliacci in giro che parlano a vanvera spaventando e mettendo rumors inutili e inutilmente provocatori? Si purtroppo questa è la verità….
la premessa
Da infiniti anni, i sistemi operativi avevano il supporto per un numero limitato di file e di codec multimediali implementando al loro interno codec necessari per vedere tali file dalle utility di sistema, nel tempo i diversi codec si sono ridotti notevolmente a pochi codec, e molti non sanno, che spesso erano stati installati da applicazioni di terze parti, ad esempio Windows non ha mai pagato le royalties per la lettura dei film in Dvd, codec mpg2, quindi senza l’installazione di un player dvd il lettore multimediale di windows non era in grado di leggere nessun dvd, dava errore dicendo Codec non supportato, ma nessuno ci faceva caso perchè leggeva i dvd da… un player dvd, quindi installando il programma si installavano i codec nel sistema.
Sia sotto Windows che sotto Mac la maggior parte dei codec video è sempre stata aggiunta come terza parte, e spesso anche se supportati direttamente esistevano codec di miglior qualità (la tedesca MainConcept ha fatto business su questo prima di vendere i suoi codec a Adobe).
Chiunque abbia lavorato nel video negli ultimi 20 anni conosce l’innumerevole quantità di codec, pacchetti, varianti di codec ha dovuto installare per supportare una o l’altra camera durante l’editing video.
Oggi girando prettamente in h264 e varianti, tutto sembra per magia supportato e quindi tutto compatibile (che poi non è vero perchè h264 a seconda del decoder software hardware può essere letto con piccoli errori e differenze qualitative).
La realtà, oggi 1 dicembre 2018
Apple con il sistema operativo successivo a Mojave abbandonerà completamente il framework Quicktime 32bit, e completerà il passaggio iniziato anni fà a AvFoundation framework 64bit, con il risultato che tutti i software collegati al vecchio framework smetteranno di funzionare.
Cineform, dnxHD/Hr e molti altri codec erano implementati nel sistema installando esternamente delle risorse che si appoggiavano al vecchio QuicktimeFramework.
Ora noi abbiamo un problema? No, la situazione è come era prima, perchè si implementavano i codec come terze parti nel sistema per vedere da finder o da altri programmini i filmati, ma i software importanti implementano internamente i codec senza dover dipendere dal sistema, come ho spiegato negli articoli zuppa di codec precedenti.
Un buon flusso di lavoro prevede che tutto il lavoro sia fatto in modo ordinato ed efficiente tramite i software di ingest ed editing, per fare una rapida cernita del materiale, introdurre tramite metadata le informazioni di lavoro, e organizzare il materiale copiandolo, transcodificandolo e gestendolo senza dover passare per il sistema operativo.
Per chi ancora vuol passare per il sistema operativo, basterà che usi una qualunque applicazione come VLC che include già tutti i codec per leggere i file, anche se si lavora in ambito montaggio e post ha più senso usare software di lavoro per vedere il materiale e giudicarlo, che usare player di sistema o altri elementi che possono alterare, mostrare il materiale nel modo non corretto.
La realtà, oggi 11 dicembre 2018
Apple ha trovato un accordo con Adobe riguardo il prores, e nelle nuove release di Adobe Premiere, After Effects, MediaEncoder etc potranno scrivere file in prores anche sotto Windows, a dimostrazione che si vogliono estendere le possibilità e non chiudere come tanti affermano.
Oggi molte aziende ci costringono ad essere ostaggi dei loro software, delle loro scelte ma soprattutto dei loro ERRORI!!!
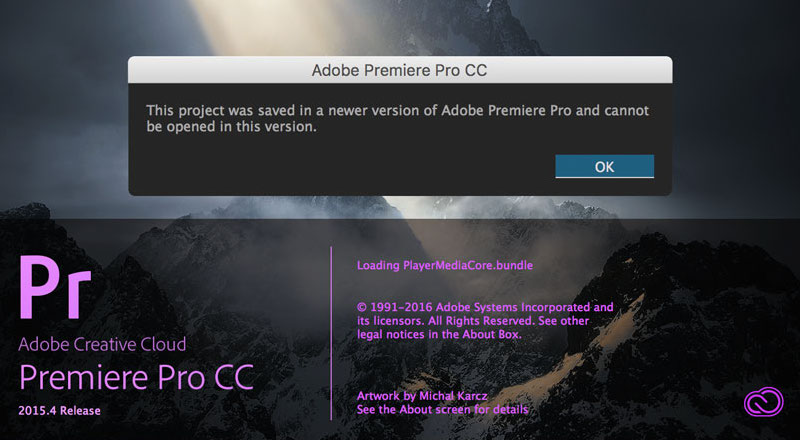
Tempo fà i formati con cui si salvavano i progetti di postproduzione, di montaggio, di grafica avevano un minimo di retrocompatibilità, ma oggi siamo forzati ad usare l’ultima versione del programma altrimenti è impossibile leggere un file realizzato anche solo con una versione successiva.
Il problema nasce dal fatto che oggi più che 10 anni fà gli sviluppatori sono diventati delle vacche (termine italiano, mucche è un volgarismo tratto dal fiorentino ed erroneamente assurto a termine italiano pensando che sia meno volgare del termine vacca) da mungere da un programma all’altro, e quindi oltre ad avere la frustrazione di esere spostati da un programma all’altro, alla difficoltà di dover metter mano ogni 6 mesi a codice non loro e spesso non commentato, si sono impigriti e sviluppano i software sempre peggio.
Spesso sento programmatori che protestano di questa mia denominazione, ma non sanno poi rispondere di fronte all’evidenza di programmi che producono sempre più errori e problemi riversando sull’utente finale il problema di esportare il lavoro finito in condizioni decenti o combattere con tutti i bug che fanno chiudere il programma mentre uno lavora.
Molte aziende tolgono la retrocompatibilità con la scusa che nelle versioni vecchie mancano certe funzionalità, io rispondo che se nei programmi nuovi funzionassero le vecchie funzionalità, non avrei motivo di fare dei downgrade per completare il mio lavoro…
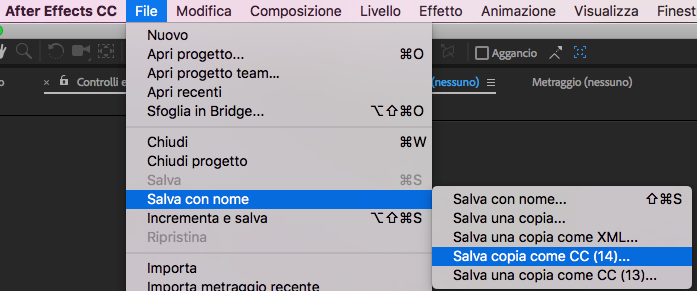
Comunque oggi vediamo un modo poco evidente di fare downgrade di progetti, per due software Adobe : After Effects e Premiere
After effects per fortuna prevede aprendo anche nella 2018 di andare su file / salva con nome
e presenta sia la versione 2014 che la cc. Non è un caso della scelta di questi due formati, infatti con la 2014 Adobe ha concluso lo sviluppo di diversi addon e software sia per Premiere che AfterEffects, ha smesso lo sviluppo multiprocessore e multicore, quindi se aprite After 2015 e lo vedete più lento, ecco spiegato il motivo…
La versione CC prevede di salvare anche per CS6, in modo da poter essere compatibili con i progetti realizzati in passato e poter collaborare con chi ancora ha deciso di continuare con un prodotto che aveva raggiunto la sua stabilità produttiva sia in stabilità che velocità.
Premiere è un programma per montatori, quindi ovviamente meno complesso di un programma di compositing, per questa ragione Adobe ha preferito evitare questa trafila, non permette proprio il salvataggio per le vecchie versioni del programma Premiere…
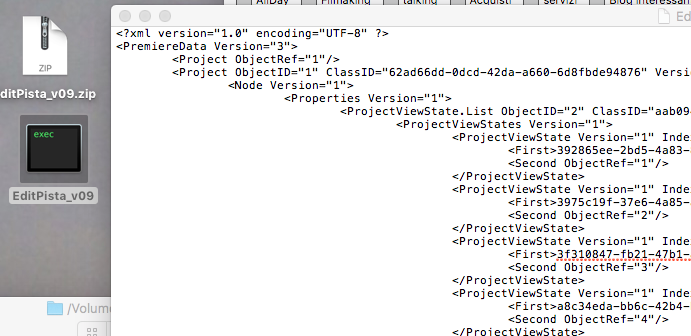
Esiste un trucco per ripristinare la compatibilità, un trucco banale e semplice, ma pochi lo conoscono :
Il file di premiere è un xml compresso con Gzip, quindi è possibile editarlo con un banale editor di testi. Di default un file Premiere viene salvato con estensione “prproj”, ma rinominandolo “.zip” sarà possibile scompattare e leggere il file di testo contenuto in esso. Aprendolo con un editor xml o di testo che non alteri il formato, dal semplice text edit di windows all’editor di testi del mac, basta cambiare nella quarta riga la voce finale di version al valore 1, da
in questo modo all’apertura premiere penserà che sia un file del primo premiere, leggerà tutto quello che può interpretare e scarterà le voci non conosciute, permettendoci di aprire il file in ogni versione di premiere windows e mac.
Importante è rimettere (senza ricomprimere non serve e se non usate gzip darà errore) l’estensione “.prproj”.
Una informazione banale ma non troppo è che il sistema cloud prevede di installare le vecchie versioni dei pacchetti, ma non in contemporanea, il che comporta diversi disagi e tempi pressochè infiniti, ammenochè… voi non torniate indietro nel tempo e utilizzate i metodi vecchia scuola, ovvero l’installer…
apparentemente Adobe non rende disponibile direttamente gli installer dei vari pacchetti della cloud, ma per fortuna esiste un sito dove abbiamo la possibilità di trovare i link ufficiali sul sito Adobe per scaricare le diverse versioni dei programmi della suite Cloud.
Oggi con la fisima della nitidezza e della definizione inoculata dal marketing, se non abbiamo un telefono che riprende in 8k (per mostrarlo sul display magari neanche fullhd, compresso), se non facciamo riprese panoramiche da 12k (combo di Newyork girato con 3 red 8k), non abbiamo immagini definite.
Dall’altra parte abbiamo persone che fanno studi scientifici sulla capacità visiva dell’occhio e confrontando in modo diretto le immagini delle diverse camere dimostrano che a parità di pixel non è detto che abbiamo realmente immagini più definite, anzi in certi casi diventa il contrario, motivo per cui Arriflex con la sua Alexa, 2,7k e 3.4k in openGate spesso offre immagini più nitide di quelle catturate con cineprese digitali 8k.
Senza fare il pixel peeper, lasciando queste seghe mentali ad altre persone, visto che il mio obiettivo primario è la narrazione per immagini, vediamo di capire brevemente quali sono i fattori che permettono di esprimere al meglio la nitidezza e l’acutezza di una ripresa (indipendentemente da fattori umani).
fattore 1 : la lente
La lente può (condizionale) determinare la qualità dell’immagine perchè è il sistema con cui si cattura la luce, la focalizza e la proietta sul piano focale (pellicola o sensore). La qualità delle lenti oggi è abbastanza lineare, per cui la differenza può essere la luminosità della lente, ma usata nel modo corretto (vedi il fattore 2), una lente media offre una buona definizione senza dare grandi limitazioni sulla nitidezza, a patto che :
la lente sia pulita e non abbia elementi estranei sopra
che non ci sia luce laterale (non protetta da paraluce e mattebox) che abbatte il contrasto
che non ci siano filtri di bassa qualità che riducono la definizione iniziale della lente, spesso si usano filtri neutri di qualità non ottimale, che riducendo la luce la diffondono togliendo nitidezza all’immagine originale.
che sia correttamente calibrata per proiettare sul sensore l’immagine (alcune lenti soffrono di problemi di pre/back focus, ovvero l’immagine viene proiettata poco prima o poco dopo il piano focale, quindi per centesimi di mm di tolleranza l’immagine è più morbida perchè non allineata col piano focale
che la lente sia perfettamente allineata (in alcuni casi le lenti possono essere leggermente angolate rispetto al piano focale causando una perdita di definizione su uno dei lati in alto, o in basso, o a destra, o a sinistra.
In un precedente articolo avevo fatto una disanima tra diverse lenti, da lenti vintage a lenti medie, e una lente di fascia più alta senza riscontrare una differenza di nitidezza percepibile nell’uso comparato: stesso diaframma, stessa situazione, stesso sensore, stesso soggetto.
fattore 2 : il diaframma
Quando si gestisce la ripresa troppe persone dimenticano che le regole di fotografia valgono sempre, indipendentemente dalla qualità dell’attrezzatura. Molti oggi sanno che il diaframma gestisce la luce in ingresso definendo se farne entrare tanta o poca, e di conseguenza alterando anche la profondità di campo. Ho spiegato in modo più esteso in un altro articolo sull’esposizione questo discorso, ma in molti non sanno come cambiando il diaframma si possa entrare in un campo di alterazione della luce che genera la DIFFRAZIONE e come possa essere il limite della propria ripresa.
In breve cosa è la diffrazione?
Quando si chiude il diaframma di un valore maggiore di X il dettaglio di luce proiettato sul diaframma non si concentra ma si diffonde, per cui un punto chiaro su una superficie scura non è più nitido ma sfuocato. Tradotto in soldoni c’è troppa luce e chiudo il diaframma pensando di ridurla, ma man mano che chiudo il diaframma perdo nitidezza, quindi a diaframma 22 la stessa immagine sarà sfuocata rispetto a diaframma 11 come se avessimo applicato un filtro di diffusione o di blur.
Come si gestisce la diffrazione?
Dato che la diffrazione appare da un certo diaframma in poi si tratta di scoprire quale sia il diaframma limite della propria lente, in funzione del proprio sensore. Un semplice e comodo calcolatore di diffrazione lo potete trovare in questo interessante articolo sulle lenti e le loro caratteristiche.
Comunque per semplificare la vita a molti di noi, una semplice tabella per avere un riferimento, poi da lente a lente può esserci più tolleranza. Risoluzione vs Dimensione
Risoluzione Sensore
Sensore 4/3
Sensore s35
Sensore 24×36
FULL HD
f/18
f/26
f/32
4k
f/9.9
f/12
f/18
4.6k (UMP)
f/11
5.7k (eva1)
f/8.8
8k (Red Helium)
f/9.4
Come si può notare non si parla di diaframmi particolarmente chiusi, se non alle basse risoluzioni, il che diventa particolarmente divertente notare come con l’aumentare della risoluzione si abbassa la possibilità di chiudere il diaframma, altrimenti si crea diffrazione, catturando una immagine progressivamente più sfuocata pur aumentando il numero di pixel catturati. Attenzione che per risoluzione si intende la risoluzione del sensore, non della cattura del filmato, perchè la dimensione dei fotodiodi o dell’elemento che cattura la luce influenza in modo diretto la nitidezza delle immagini.
Per questa ragione quando si lavora con le cineprese digitali il filtro neutro è un elemento fondamentale e indispensabile per preservare la nitidezza originale, e contrariamente a quello che credono molte persone, le dslr non sono così comode avendo un gran numero di pixel da cui ricavare un formato fhd, perchè se usiamo una fotocamera che registra in fhd ma il sensore è un 24mpx, quello è il limite da usare per scegliere il diaframma di ripresa e mantenere il massimo della nitidezza possibile, a questo proposito la mirrorless ottimale per il video è quella creata da sony nella serie A7s perchè pur usando un sensore fullframe ha una risoluzione di ripresa corrispondente all’output, ovvero 4k, e quindi meno sensibile alla diffrazione di una A7r che con 36 e 54 mpx tenderà ad avere il triplo e il quintuplo dei problemi.
fattore 3: il sensore
Il sensore, la sua tipologia, la sua risoluzione possono influenzare la nitidezza catturata, quindi ovviamente se il sensore è a misura della risoluzione di uscita il risultato sarà migliore. La maggior parte dei sensori sono strutturati da una matrice detta Bayer, nella quale si cattura un segnale monocromatico e poi filtrandolo si ricavano i colori, per cui abbiamo il verde che rappresenta la luminanza che possiede buona parte delle informazioni, mentre gli altri due colori sono ricavati ecatturati parzialmente, per cui si dice che comunque un sensore xK abbia una reale risoluzione di 2/3 dei K originali e poi venga fatto l’upsampling effettivo dei pixel. Il che tecnicamente è vero, ma non è un reale problema. Esistono sensori fatti come wafer dei tre sensori (uno per colore) che catturano separatamente le componenti colore RGB che spesso offrono immagini di ottima nitidezza. Esiste poi la scuola di pensiero del downsampling, ovvero catturiamo con un sensore di dimensioni maggiori, ad esempio 4.6k, 5,7k e poi da questo ricaviamo alla fine un segnale in 4k o 2k o fhd, in modo da sovracampionare le informazioni e avere una maggior precisione e dettaglio. La semplice prova di forza o applicazione muscolare degli X k non è fonte sicura di qualità o di dettaglio, inoltre con l’aumentare della risoluzione e non delle dimensioni del sensore incontriamo il problema della Diffrazione (come abbiamo visto prima), e il problema della sensibilità, perchè la stessa lente deve distribuire la stessa luce su un numero maggiore di fotorecettori, quindi ogni elemento riceve meno luce o con meno intensità.
A livello teorico maggior numero di pixel correttamente gestiti nella cattura può corrispondere ad un maggior numero di dettagli, a patto che utilizzi la risoluzione reale del sensore, cioè i pixel catturati siano esattamente la matrice del sensore. Le eventuali elaborazione del segnale prima della registrazione (raw o sviluppata) possono inficiare la nitidezza del segnale. Esistono diversi tipi di amplificazione del segnale e durante quella fase (analogica o digitale) si può alterare la percezione di nitidezza.
fattore 4: la compressione
Una volta catturate le informazioni, queste devono essere in qualche modo registrate, e pur partendo da sensori con un’alta capacità di cattura di dettaglio, o d’informazioni (spesso 16bit lineari) poi la registrazione delle informazioni viene ridotta a 14-12bit raw o 10bit compressi con algoritmi varii che per ridurre il peso dei file andrà a alterare in modo più o meno significativo le nitidezza delle immagini. Ogni camera ha i suoi algoritmi di compressione, molti nelle cineprese si basano sul concetto della compressione wavelet, che sia raw o no, per impedire la formazione di blocchi di tipologia più “digitale” come la compressione mpeg che genera blocchi di dati a matrici quadrate, questo ottimo tipo di trasformata nel momento in cui si comprimono i dati tende man mano che si aumenta la compressione a rendere più morbido il filmato. Naturalmente quando si parla di morbidezza parliamo di finezze, non certo di avere immagini sfuocate. Molti Dop quando usano le camere Red scelgono di usare compressioni più o meno spinte in alternativa all’uso di alcuni filtri diffusori per rendere più piacevoli le immagini.
Quindi facendo una ripresa o una fotografia, non possiamo strizzare i dati in poco spazio e pretendere di avere il massimo delle informazioni, del dettaglio, della definizione. La scelta dei formati di compressione è molto importante e conoscere le differenze tra i diversi formati di compressione e le loro tecnologie applicate alle diverse camere è importante per poter gestire correttamente la qualità di partenza iniziale. Alcuni formati a compressione maggiore (h264/5) generano artefatti a blocchi, mentre le gestioni dei formati wavelet possono ridurre la nitidezza dell’immagine man mano che si aumenta la compressione, ma in modo molto leggero, tanto che molte compressioni wavelet vengono definite visually lossless
fattore 5: la lavorazione
Le lavorazioni dei file possono alterare la percezione della nitidezza se vengono create più generazioni dei file originali non utilizzando formati DI di qualità per lo scambio e l’esportazione dei materiali. L’applicazione di effetti o lavorazioni con sistemi non professionali può causare ricompressioni non volute, downscaling e downsampling colore che possono influenzare la nitidezza originale. Inoltre ci sono fasi molto delicate come il denoise che in certi casi può essere troppo forte o troppo aggressivo e come tale tende a mangiare non solo il rumore, ma anche il dettaglio fine.
fattore 6: il delivery
Un fattore poco conosciuto è la scalatura dinamica dei flussi video, soprattutto quando si guardano i film in streaming legale. Il file alla fonte ha una risoluzione e una compressione, ma durante la trasmissione se ci sono problemi di segnale, rallentamenti, problematiche varie il segnale viene istantaneamente scalato per impedire che il filmato vada a scatti o in qualche modo possa influire sulla visione generale, quindi da una scena all’altra potrebbero esserci delle variazioni consistenti della qualità e i sistemi di contrasto dinamico andrebbero ad amplificare ulteriormente i bassi dettagli. Se abbiamo un prodotto stabile e lineare come un bluray o un bluray 4k abbiamo la certezza che la qualità sarà sempre costante, mentre se usiamo una distribuzione differente delle perdite di qualità potrebbero essere causate dalla trasmissione variabile.
fattore 7: la fruizione
Un fattore che tanti sottovalutano, spesso causa del danno finale, sono i metodi di fruizione del materiale video. A partire dal dispositivo di visione, che spesso altera in modo più meno significativo l’immagine, vedi l’articolo sui televisori da telenovelas, al metodo di gestione delle informazioni. Quando vediamo una immagine non sappiano se il pannello è a misura per l’immagine che stiamo vedendo, il che può essere causa di alterazione di vario tipo, perchè dovrà essere scalata in realtime con diversi algoritmi più o meno efficienti nel mantenere il dettaglio o perderlo. Spesso abbiamo televisori 4k che mostrano materiale fhd (1/4 delle informazioni) o peggio sd (1/16 delle informazioni). Il danno però nasce dal fatto che tutti questi televisori applicano le funzioni di oversampling anche quando una immagine ha realmente la dimensione del pannello, quindi anche se apparentemente sembrano ancora più nitide, in realtà gli effetti dei vari algoritmi di sharpening tendono a creare nuovi “FINTI” dettagli che sovrascrivono e cancellano i dettagli originali.
Spesso ci sono tanti parametri attivati a nostra insaputa, o peggio abbiamo la difficoltà di disabilitarli, perchè solo in determinate combinazioni di visione sono modificabili. Ci sono prodotti di fascia alta che è possibile disabilitare le maschere di contrasto e i vari algoritmi di contrasto solo con i segnali in ingresso HDMI, non per i segnali interni o da stream internet interno… il che è può essere imbarazzante con i segnali 4k da Netflix che sono ottimi e non richiedono ulteriori process, anzi…
E’ ironico notare come spesso la critica parli male di un genere che dà spesso l’occasione agli attori di emergere : l’Horror
Il futuro Villain per Tarantino
Il genere spesso ricade nel low budget, soprattutto rispetto alle produzioni classiche, quindi gli attori emergenti spesso fanno delle parti nel genere dove nomi più altisonanti non sono gestibili con i budget ridotti del genere Horror.
Qualche nome? Giusto per non cadere nel generico, o parlare di attori che poi sono noti solo agli amanti del genere? E comunque ogni grande attore ha avuto la sua capatina nel genere, più o meno nobile dell’horror.
Brad Pitt esordisce giovanissimo, ma la sua stella inizia a brillare con Intervista col vampiro nel 1994 con Tom Cruise
Charlize Theron, oggi riconosciuta grande attrice dopo l’oscar di Monster e l’interpretazione in MadMax Fury Road, ha esordito in The children of the corn III
Il grande Jack Nicholson, iniziò nel 1960 nella Piccola bottega degli orrori, per arrivare ad essere diretto da Kubrik nel 1980 in The Shining, fino a trasformarsi poi in Lupo mannaro nel 1994 in Wolf
Jamie Lee Curtis è una delle prime donne che rivoluzionano l’assioma vittima carnefice nel 1978 in Halloween di John Carpenter
Jennifer Aniston nel 1993 è spaventata a morte dal Leprechaun prima ancora di essere Rachel di Friends
Johnny Deep prima di essere il feticcio di Tim Burton e Jack Sparrow era una delle prime vittime di Freddy Krueger in Nightmare on Elm street del 1984
John Travolta, prima delle febbre del sabato sera, faceva i suoi primi passi sul set di Carrie di Brian de Palma
Kate winslet, prima di salire sul Titanic per interpretare Rose, era stata una delle muse del fantahorror di Peter Jackson Creature del cielo nel 1994
Keanu Reeves, prima di essere immortalato in Matrix, prima di essere la star di azione con Speed, e poco dopo essersi trasformato in un sex symbol in Point Break, è interpretando Jonathan Harker in Dracula di Coppola nel 1992 che diventa un mito
Kevin Bacon ha l’onore di essere una delle prime vittime di Jason nel 1980 in Venerdì 13
Leonardo di Caprio prima di essere il divo di MrGraves e Titanic combatte i criceti spaziali in Critters 3 nel 1991
Liam Neeson prima di essere consacrato al grande pubblico con Schindlers’ List era il dott Peyton WestLake, il supereroe horror di Sam Raimi Darkman del 1990, e ancor prima, nel 1988, nella commedia fanta horror High Spirits con Peter O’Toole e Daryl Hannah
LindaHamilton, prima di abbattere Terminator, era presente nel 1979 in Wishman, e poi era la protagonista in Children of the Corn 1984 prima di girare il primo Terminator
Luke Perry, che in tv è il Dylan dietro cui tutte le ragazzine morivano, al cinema esordisce un paio di anni dopo, nel 1992 con il film di Buffy l’ammazzavampiri
Meg Ryan prima di essere la fidanzatina d’america era l’amichetta della bimba nella casa infestata di Amitiville 3 D
Michelle Pfeiffer frequenta da sempre il genere, la vogliamo ricordiamo per Scarface 1983, o per essere stata la deliziosa Isaboe in LadyHawk, o Sukie Ridgemont in Le streghe di Eastwick, per poi diventare una affascinante lupa mannara in Wolf in compagnia di Jack Nicholson, e poi ancora in Dark Shadow di Burton,
Mila Kunis affronta nel 1995 in piranha per farsi largo nell’oceano del cinema
Robert De niro, anche se non a inizio carriera, non ha disdegnato l’interpretazione del mostro di Frankestein, in contrapposizione al dottore, interpretato da Kenneth Branagh nell’omonimo film Mary Shelley’s Frankenstein
Scarlett Johansson prima di diventare la Vedova Nera era una teenager nel film di genere Arac Attack nel 2002
Sharon Stone nel 1981 viene portata alla ribalta da Wes Craven in Benedizione mortale
Sigurney Weaver aveva già fatto qualche film, ma il masterpiece che l’ha lanciata è stato il primo Alien di Scott nel 1979
Tim Curry, istrionico, versatile artista ha attraversato ogni genere e personaggio, ma per i più resta il dott Frank-o-furter di The Rocky Horror Picture Show
Tom Cruise era già noto al grande pubblico con risky business, ma il salto di qualità lo fa diretto da Ridley Scott in Legend
Winona Ryder deve il suo lancio alla commedia horror BeetleJuice di Tim Burton nel 1988 e poi in Dracula di Coppola nel 1992
il nostrano Zingaretti esordisce in una produzione horror italo americana Castle freak.
Insomma questa piccola carrellata per ricordare come il cinema di genere horror sia sempre stato prolifico di attori, registi, etc ma spesso si ricordano per le altre interpretazioni… dopo tutto già alla nascita del cinema si possono contare un sacco di horror, nel 1890 …
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.


 Sono anni che parlo dei prodotti BlackMagic Design, e ho dedicato tanti articoli alla Pocket 4k, una innovativa camera che registra in prores, Braw, e ha cambiato il modo di lavorare di tante persone.
Sono anni che parlo dei prodotti BlackMagic Design, e ho dedicato tanti articoli alla Pocket 4k, una innovativa camera che registra in prores, Braw, e ha cambiato il modo di lavorare di tante persone.